25 October 2020 - Updated dataset v8
Fixed bugs in natural number parsing. It affects the number of seconds of life of the video recommended, and the number of views.
14 October 2020 - Definitive version of our publication.
YTTREX-crowdsourced analysis of YouTube’s recommender system during COVID-19 pandemic.
14 September 2020 - Our paper get accepted with surprisingly good review!
Check out data collected the 25th and 26th, in JSON and CSV.
18 July 2020 - First qualitative analysis embedded into dataset (English only)
Now the field qualitative might assume three value: ‘relevant’, ’linked’, ‘off-topic’; we pass trought all the videos suggested by YouTube on the right column, only concerning the BBC English video of our experiment.
Qualitative analysis attribution criteria:
- relevant: the video talk actually about covid-19, coronavirus, lockdown, etc..
- linked: the video has another subject, but it is linked because talks about health, past pandemincs.
- off-topic: anything else.
You can get the files named ‘qualitative’ from the dedicated repository, and this public tableau simple visualization might help third party revision. Below, a complete cell from file qualitative-ωτ1-v7.json.
{
"evidence": 0,
"login": true,
"id": "c8eecebbdcd9badcafdc",
"savingTime": "2020-03-26T21:33:58.071Z",
"clientTime": "2020-03-27T02:45:01.000Z",
"uxLang": "es",
"recommendedId": "2f577cef26c0e61ec54ac3ad725dafb5104fc6cf",
"recommendedVideoId": "BtN-goy9VOY",
"recommendedAuthor": "Kurzgesagt – In a Nutshell",
"recommendedTitle": "El Coronavirus Explicado & Qué Deberías Hacer",
"recommendedLength": 30900,
"recommendedDisplayL": "8:35",
"recommendedLengthText": "8 minutos y 35 segundos",
"recommendedPubTime": "2020-03-20T02:45:01.000Z",
"recommendedRelativeS": 604800,
"recommendedViews": 17854,
"recommendedForYou": true,
"recommendedVerified": true,
"recommendationOrder": 1,
"recommendedKind": "video",
"watchedVideoId": "A2kiXc5XEdU",
"watchedTitle": "How do I know if I have coronavirus? - BBC News",
"watchedAuthor": "BBC News",
"watchedChannel": "/user/bbcnews",
"watchedPubTime": "2020-03-21T00:00:00.000Z",
"watchedViews": 682214,
"watchedLike": 6331,
"watchedDislike": 223,
"hoursOffset": 47,
"experiment": "wetest1",
"pseudonym": "nachos-taco-manicotti",
"step": "English",
"top20": true,
"isAPItoo": true,
"thumbnail": "https://i.ytimg.com/vi/BtN-goy9VOY/mqdefault.jpg",
"qualitative": "relevant"
},
2 July 2020 - Released dataset v7, and youtube official API historical data.
- Added
thumbnailURL. - Added
isAPItoo(true|false) by comparing if the recommended videoId is also among the related videoId returned by the official youtube API. We retrieve the data on the 25th of March, the day of the experiment. - Added
sessionIdto link and filter only complete session. - Added
hoursOffseta number of hours starting from 0 till 47, it represents time as offset. 0 is the beginning of the experiment (midnight, 25th of March). The software culculate fromsavingTime. Note, we didn't useclientTimebecause that's bound to the timezone, our server is in GMT-0. - Added
top20: a boolean field that tells if the evidence has arecommendationOrderlesser than 20. 20 it is the default amount of recommended display to every watcher, and *optionally*, if a watcher scroll down, youtube send more recommendations. - Consider
recommendedIdandidare both equivalents as a unique identifiers.
The new released data
- Session file: only 66 unique profile complete a session, we are not considering additional session per tester, at the moment. This amount is quite small considering the effort we put on this [swearing].
- Youtube official API: in the 25th of March we fetch the youtube API to see what the company was declared as ‘related’. Our goal was to reproduce this (2019) venn diagram equivalence,
On fact-checking + crowdsourcing
To judge youtube quality selection, we need people understanding Chinese, Arabic, and all the languages of the experiment and manually review the recommended videos. This crowdsourced qualitative assessment should give an indicator on how Youtube claims and methodology are accurate.
At the moment we can’t organize such review, but if any partner display such interest youtube-team at tracking dot exposed.
By reading analysis such as Saudi Arabia sstate media and covid-19, or Pandemics and chinese-attributed propagand, it is clear Youtube can’t do qualitative analysis with their machines. Artificial Intelligence isn’t suitable to addess this problem. Until we do not prove it, any company would keep claiming they address content curation with “better algorithm” altought should be clear this is not technically, and logically, possible.
17 June 2020 - Relased dataset v6
Uh? Three months of silence and six version jump? What does it mean? A difficult task and experiment were about transforming human-readable strings into ISOData format. Now we have got a unique shiny piece of technology to further integrate into the browser extension. It has been an intense stream of work in between other tasks, such as fundraising. Now there is a bunch of new shiny metadata, notably:
The distance in seconds between the user-watching-moment and the publication date of the related video. A researcher now might sort by newest-oldest recommendation. The publication time in ISODate format. Number of views of recommended video in integer. Likes and Dislikes of the watched video in integer, and please check the big link below to see more.
27 March 2020 - 🎆 Test completed! 🎆
🎆 Thanks to everybody contributing and spreading the experiment 🎆
Since then, we have released the data, extended the dataset as much as we feel it helpful, and improved how it is openly accessed. We’ll keep updating this page.
Anonymization and data release
The purpose of this dataset is a research on personalization algorithms. The dataset has not and do not aim to have personal data. What follows is a brief description on how do we work to avoid to keep volunteer’s personal data.
We should consider that among the ‘related content,’ YouTube may likely recommend something related to previous individual activities. Is it very possible that Youtube already creates a curated selection so personal, that may link to an individual uniquely. Could that de-anonymize a subject or an interest of a data subject? The answer is, “maybe if supported by an out-of-band leak.”
But, even in the worst-case scenario, we estimate this can’t lead to a leakage of personal data,
The purpose of this dataset is the research on personalization algorithm. The dataset has not personal data, despite the fact that the personalization of YouTube depends on personal data (thus, legally acknowledged as data subject).
de-anonymization attacks such as relinking by searching for known patterns is not considered feasable because: Attacker should know how patterns appears on Youtube personalization algorithm and this is not known. Youtube himself, a property of Alphabet inc., is likely to be the only entity who might be interested in de-anonymize volunteers, but we estimated they might already have such knowledge if they really want to have it.
We believe that People supporting the experiment would not be exposed to a risk for participating, as it is, at the moment, aimed to a still explorative scientific research.
note checkout public stats if curious un how we doing, or in the github repository.
27 March 2020 - Release of video data (first day partial)
λ node scripts\wetest1-basic.js --type video
wetest-1-basic — [video] is the target: starting wetest basic extractor… +0ms
lib:mongo3 Initializing mongoUri with mongodb://localhost:27017/yttrex +4ms
wetest-1-basic — Completed DB access to fetch: {"savingTime":{"$gte":"2020-03-24T23:00:00.000Z","$lte":"2020-03-26T23:00:00.000Z"},"type":"video","videoId":{"$in":["Lo_m_rKReyg","Zh_SVHJGVHw","A2kiXc5XEdU","WEMpIQ30srI","BNdW_6TgxH0"]}}: 402 objects retrived +2s
wetest-1-basic — Unnested the 'sections' return 11563 evidences. Saving JSON file +438ms
wetest-1-basic — Produced 5218168 bytes for text/csv, saving file +820ms
Get the files. Soon we’ll release day 1+2 and document the format.
26 March 2020 — First day, a few statistics and a partial data release
At the end of day 1, we see a smaller contribution compared to pornhub collaborative test. Considering our 13 days before the weTEST day, we had an average of 79.3 daily adopters. Yesterday 168 people active, 72 new installations, likely each of them start to do the test.
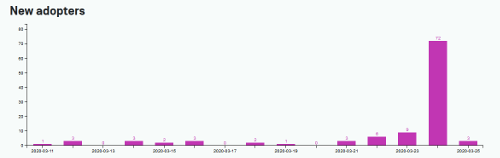
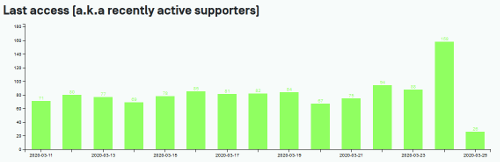
Data analysis and Data format
Assume a person starts the test: open homepage, open five links, what if forget the 2nd links? Since 26th early morning, we di not had visual feedback to remind you which links you already clicked. And we notice, for example, the Chinese-language-Codiv video has five access more than the Arabic. Does it means someone start the test and abandoned? Or our system has a small percentage of failures? Or that video wasn’t loaded from youtube? We don’t know. But does this precision matter? should we clean the dataset of the incomplete session? A complete session being with accessing the homepage, in the right sequence, access the five videos, and it concludes with the homepage again.
We distinguish between Session-centered dataset it considers only complete sessions composed of seven observations each. Page-centered dataset do not consider the session. It keep in account video and homepage evidence, good as they are, indiviudual decontextualized observed evidence. Basic researches on diversity and content analysis can start with this.
Session-centered dataset
To extract the session we are working on a dedicated nodejs script wetest1.js; we'll complete it in the next days.Page-centered dataset
A more basic script is develop to pick, anonymized, unroll and save in JSON/CSV format. wetest1-basic.js, pick the open data , and see below the format description.
wetest-1-basic — Completed DB access to fetch: {"savingTime":{"$gte":"2020-03-24T23:00:00.000Z","$lte":"2020-03-26T23:00:00.000Z"},"type":"home"}: 507 objects retrived +2s
wetest-1-basic — Unnested the 'sections' return 18759 evidences. Saving JSON file +292ms
wetest-1-basic — Produced 4879099 bytes for text/csv, saving file +1s
YT-Home data format
On the right, you see the evidence we collected: it represent a sample of what a supporter with browser extention installed is sending to us. The censored field, publicKey and id, as treated confidentially because they are visibile only to the data subject owning this evidence.
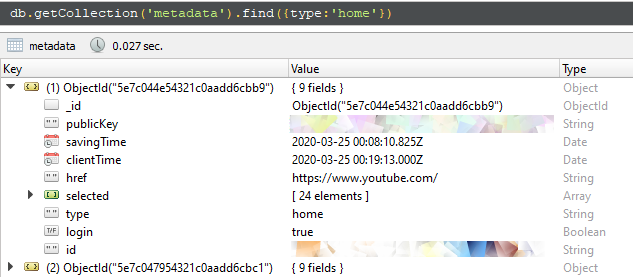
By expanding 'sections' you see the metadata we collects from each video entry appearing in homepage.
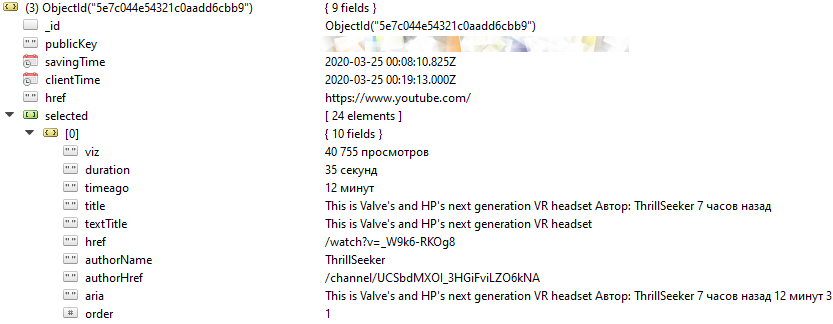
With the functions produceHomeCSV and unwindSections, we produce the anonymized dataset you can see on the right.
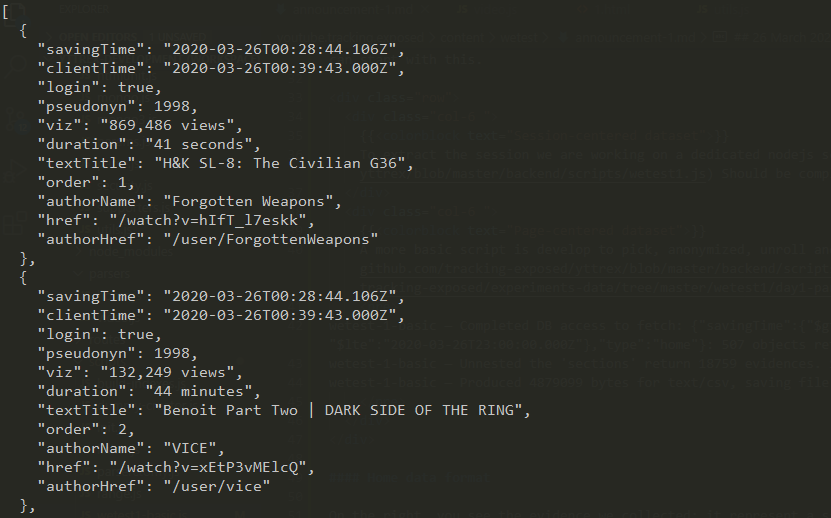
Here you can download the JSON and CSV, and the format might change in the next hours. For technical inquiry, reach out to us on github.
25 March 2020 — Coverage
Italian: Come funziona la censura di YouTube sul coronavirus?. Un esperimento del team di Facebook Tracking Exposed vuole misurare i contenuti promossi o nascosti da YouTube sulla pandemia. Ecco come diventare volontari.
Spanish: ¿Cómo funciona el sistema de moderación de contenidos algorítmico en Youtube? Ayuda a ytTREX a averiguarlo, from Derechos Digitales. ¡Hey! Necesitamos tu ayuda. El proyecto Youtube.Tracking.Exposed (o ytTREX) está aprovechando este horrible escenario de pandemia desatada por el COVID-19 para poder comprender un poco mejor cómo funciona el sistema moderación automática de contenido en hecha por algoritmos en Youtube.
25 March 2020 — Is it worked what you did?
If you want to double check your collection, click on the browser extension icon. then click on the logo in the popup. It will open the ytTREX personal page. below the pie charts and the bar chars, you should see the five video in reverse order:
25 March 2020 — Collection is open, and extended
The test starts close to the right time, and we decided to consider collections for 48 hours instead of 24 hours. 25th March 00:00 till 26th 23:59 GMT.
The public outreach is a machine slow to warm-up. If anyone in from Germany, France, Italy, all the Scandinavian, Magreb, and Balkan regional languages want to organize a similar test, get in touch.
24 March 2020 — Square tiles, for the social network, with contribution protocol
🖼️ SVG and PNG.





24 March 2020 — Protocol as a picture

23 March 2020 — Portuguese translation of the call for participation!
🎉🎉 Thanks to Narrira we got Brazilian Portuguese translation. 🎉🎉 She did it by forking this website from the github repository 🎉🎉
23 March 2020 — weTEST stickers pack!








23 March 2020 — Call for help
We released a small call for help, especially we need Chinese and Arabic expertise.
HELP ― Nothing is collective if desn't come from a group effort (before March 25th!)
- We need the most recent (March 2020), short (<5 minutes), accurate, and trustworthy video on Covid-19 in Arabic and Chinese. If you are fluent in these languages and know of a video providing vetted scientic information, Please reach out to us. We already have videos selected in Brasilian (Portugese), Spanish, and English).
- Please share the event! It should be seen by groups distant from us.
- We will release an open dataset containing all the observations from this study! Let your fellow Data analysts, open science advocates, and digital activists know about youtube.tracking.exposed! Help us keep content platforms accountable.
22 March 2020 — Research state of art
STATE OF ART ― Recent and past advancement in YT algorithm analysis
An evolving discussion among journalists and researchers is taking place regarding YouTube's accountability. First, we saw anecdotal statements; subjective stories from individuals frustrated by a perceived distortion of objective access to information. Since then, interest in the academic investigation of algorithmic bias and accountability has grown. With this study, we aim to contribute to an organic worldwide, scientific, and political experiment to shed light on how YouTube impacts our view of the world.
- The political danger of YouTube is often attributed to an article by Tufekci, Zeynep. “ YouTube, the Great Radicalizer ” The New York Times. 10 March 2018. Note, "youtube rabbit hole" concept has a long history, also seen as an opporrtunity; [try this to get rid of!?]. Most of the evidence supporting these claims is anecdotal; experiences of algorithmic interference, reported by screenshots and memories.
- A more rigorous collection of evidence, from the perspective of a single point of observation, is maintained by Guillaume Chaslot: algotransparency.org.
- At the beginning of 2020 a heated debate was seenon twitter, (Mark Ledwich, twitter announcements) Their paper reitterated the concept of YouTube as a facilitator in radicalization efforts. The methodology was limited, but reinforced the state of the art. Youtube Tracking Exposed aims to provide researchers with the data and tooling to overcome the existing methodological limitations.
- The official API isn't suitable for this analysis and limits access ot information unsuitable to exploring algorthmic bias
- We do not use 'anonymous profiles' like some research, this would miss out on critical data pertaining to the use of historical profiles in recommendations.
- We distinguish between two kind of logged profiles: the profiles with traces left by genuine human utilization, and automated data collection efforts.
COVID-19 is having unprecedented impact on life across the globe, and YouTube claims to be active in combating disinformation at a time when people are seeking to inform themselves on topics related to public health. Cultural interpretation does not scale as well as web services do, and we're skeptically of efforts for content in languages where less investment has been made. With this study we aim to explore the impact of content recommendations for public health information as it shapes the views and beliefs of non-English speakers as well.
21 March 2020 — Background experiment design
DESIGN ― Planning the experiment shape the possible findings
Don't be surprised smarter experiments might be modeled. For example, prof. Davide Beraldo and Salvatore Romano coordinated a test with logged profiles and by simulating political leaning (on what? you tell me, check out: Trexit), they recorded how YT diversify the informative experiences.
weTEST Experiment Design
Testing a personalization algorithm isn't quick and straightforward, as it seems. The researcher has to define a methodology. This method gives different values to the collected samples because they are only useful to test the assumptions initially made.
This text explores a difficult concept. It might take a while before fully interiorize the complexity of tools, restrictions, and variables tracking. If anything is unclear, don't miss the
three different methodologies lead to different dataset properties
,
what we collect and how data might be safely released
, and
data format and usages
.
Because wetest wants to be a collaborative experiment, it is smart to develop initial findings without assuming any past research. We'll start with a few concise research questions.
Inevitability, at the beginning, these question are more technical than focused on studying the political impact of the recommendation algorithms. In this initial phase we focus on developing tools and best practices.
Tracking.exposed goals aren't merely to produce reports, articles, or researches. Yes, we do it, (look at our home, bottom-left); it has been part of our training experience. Algorithm accountability can't be revolutionary if accessible only to data analyst and data protection authority. A bit of knowledge on platform influence, or algorithm literacy, should be in the modern background education, and we want to play with it.
Do you remember, companies taking a bunch of random users and experiment on them?
We'll do precisely the opposite:
a distributed crowd of random individuals, coordinated to experiment on them!
Anyone can contribute. Someone with a clean, freshly installed browser, someone else with their Google account logged. Partecipants, during the chosen day, should watch a few videos, and we'll collect the video the platform will recommend. We will run analysis to see how much diverse ends up to be suggested video.
This test - why language?
Farshad Shadloo, a YouTube spokesman, said the company’s recommendations aimed to steer people toward authoritative videos that leave them satisfied. He said the company was continually improving the algorithm that generates the recommendations. “Over the past year alone, we’ve launched over 30 different changes to reduce recommendations of borderline content and harmful misinformation, including climate change misinformation and other types of conspiracy videos,” he said. “Thanks to this change, watchtime this type of content gets from recommendations has dropped by over 70 percent in the U.S.”
In commentary such as the one above, there are two pitfalls: a language issue, and a trust issue.
Maybe YT is right, and in English language, for the US audience, Youtube investment might guarantee a quality in content curaction high enough to avoid fines, but would be that true in another language?
The exploitative business model of surveillance capitalism can't easily scale when the succes metric is the _removal of content troublesome for a precise culture_ because investing in content moderator trained and balanced in every culture in the world seems unfeasable due to high costs.
This first experiment concentrate effort in watching four videos chosen by us, on the same broad topic (covid19), in the four most used langagues in the world.
Regardless of trust, how is credible a company who promise changes, (they are invisible), and the quality assessment of such improvements comes from the same organization? Independent testing, like the one we want to enable, is an option accessible to you, to a class of students, to the FTC and to the DPAs.
We want to apply the most scientific, open, distributed approach we can aim for
Diversity is the key, but how exactly?
Personalization algorithms, content curation, and targeted experiences are unique for each of us.
Winning the fight for algorithmic independence (when you retain agency and control on the prioritization filter know as recommendation system), make sense if most of us reach that point. A minority of techno elite, literate enough to fact-check and with the skills to find the right information online, would only reinforce inequality among the people in the information age. Diversity is the key because we collectively should understand how other people are perceiving the public discourse.
A widely deployed recommendation system should be validated by a public policy. It should be subject to public scrutiny, gauging the impact on all of us. Just in 2020, the goal is not a better society but a fluid business flow in the monopolist's hand.
Algorithm analysis might seems a purely technical effort. But the platform we're operating on (Facebook, youtube, amazon) mixes social constructs with their technology, and implicitly, the limited form of algorithm analysis we can perform via passive observation, inherit complexities typical of political analysis.
Now, with wetest#1, we begin with the technical analysis, to build up a knowledge base robust enough to address political and sociological analysis. We can't yet address research questions such as "Does youtube radicalize or not people?" or "are videos with blonde white women prioritized against other demographics? It is true in any region?". We want to coordinate tests with these politically meaningful topics, but we can't yet, they aren't low hanging fruits. Releasing approximative analysis would be detrimental for algorithm literacy and platform accountability. Let's build this community with academics and digital rights defender.
If you have an idea, propose your experiment by
opening this formatted GitHub issue
, and please consider:
- we should start to measure technical conditions, and be confident in testing such variables.
- read other issues marked in the same way; this might help to understand which limits this test has.
- research questions should come from the community: concerned citizen, seasoned professional expert, to submit a proposal open a GitHub issue in our repository.