-
for Windows,
guardoni-1.8.6.exe -
for MacOSX,
guardoni-1.8.6-macos -
and for Linux,
guardoni-1.8.6-linux
chmod +x filename
to make it executable.
As we release free software, you can also run it or build it from the nodejs source.
The key aspect in any algorithm audit is a repeatable methodology: Guardoni do that for Youtube
Unsure? check out how an experiment looks like
Last update: 2021-12-02
Release version: ALPHA, 1.8.x
## 💻 How does it work?
The tool you can download is a browser that moves on its own. It navigates, at the moment this version only on youtube, following a list of paths decided by the person who is organising the analysis of the algorithm.
This automation makes it possible to repeat searches like this one (filtertube) carried out in January 2021; the analysis was described with a flowchart like this:
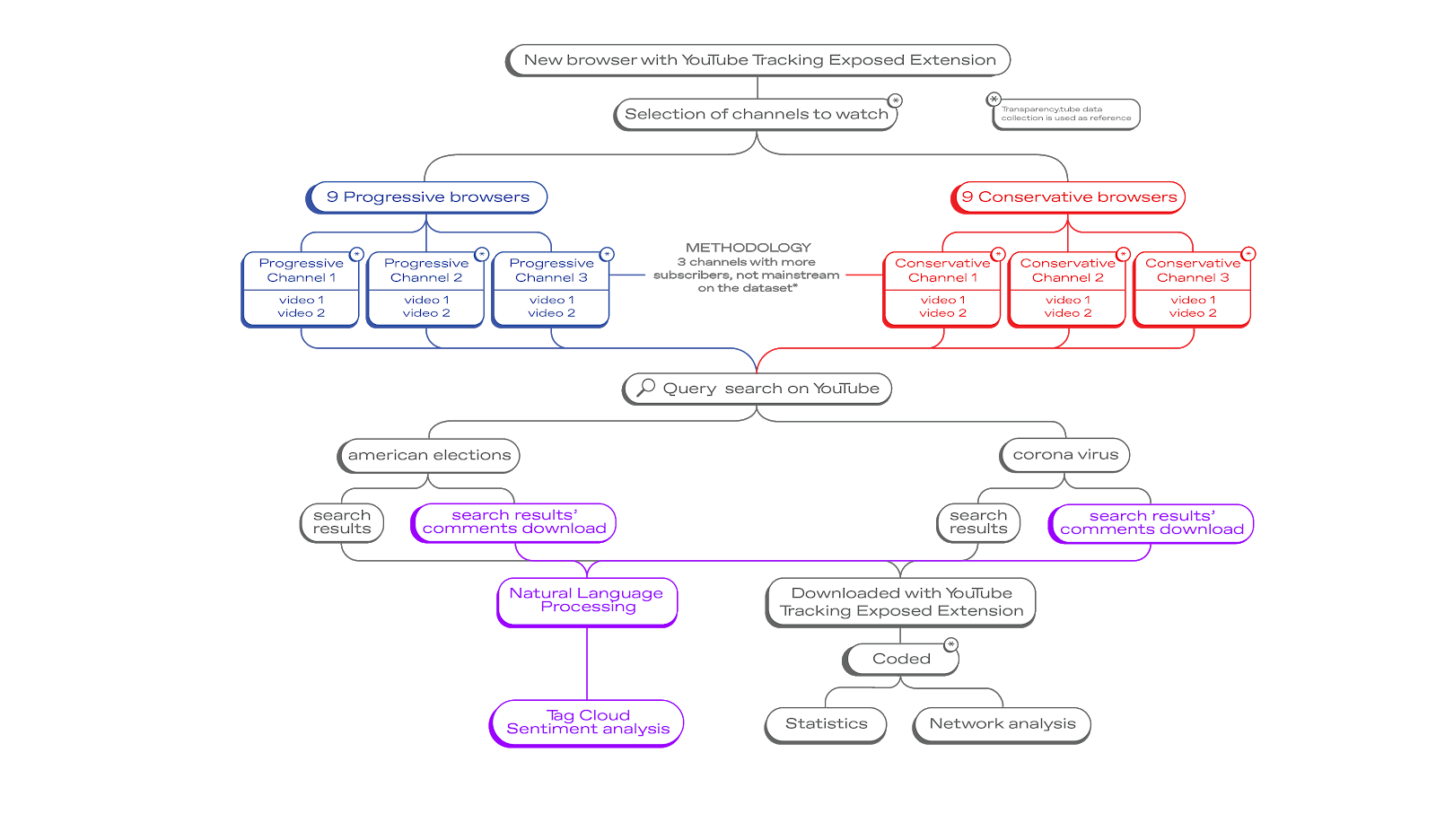
What you can do with Guardoni, is to be able to create a new profile and train it (or rather, train the youtube algorithm) so that then differences will emerge on how the final searches are answered.
The effect of youtube’s personalization algorithm has an impact on homepages, recommended videos, and search results.
## 💻 Quick command references:
You need to open a terminal and execute the file downloaded:
guardoni-1.8.4.exe –auto
If you give this command, and it doesn’t give you any error, you should see a new browser window opened with an empty page. with that browser you should go to youtube.com and accept the cookie banner.
After, comeback to the terminal, and press Enter.
The tool would not reproduce automatically a few videos selected, they belong to an experiment. An experiment is a list of youtube URLs (homepage, search queries, video watching) and in the next chapters you’ll understand how to build your own experiment, and how to download the results.
## 💻 How to practically use it
If you consider the flowchart above, to repeat the experiment you need to create two files (one would be used to train what you can consider a conservative profile, and the other a progressive.)
| Step | Progressive | Conservative | Reason |
|---|---|---|---|
| 1 | Watch a video you consider progressive | Watch a video you consider conservative | This is to "train" youtube into believing the profile like that content. |
| 2 | Watch a 2nd progressive video | Watch a 2nd conservative video | ... same. |
| 3 | Watch a 3rd progressive video | Watch a 3rd conservative video | ... same. |
| 4 | Search for "happy" | Search for "happy" | Or any more meaningful term |
## 💻 Where is the algorithm analysis?
Thanks to this collection system, searches for the keyword at position 4 will be saved, and you will be able to see how profiles that have been trained in one way rather than the other know how to receive personalised answers.
The analysis takes place when, after navigation is completed, you download a CSV file containing all the different observations. Each profile you run contributes to the observations.
We have organised a simple test that talks about climate change and climate alarmism. For this we have created two CSV files which are necessary to define how the profiles should behave.
## 💻 How to run your first actual experiment
We did two CSV files to represent different “orientations”, in this case, on the climate debate. In this case, we focus on a few video about Greta Thunberg and a the same number featuring Naomi Seibt.
urltag, watchFor, url
greta1, end, https://www.youtube.com/watch?v=v33ro5lGHQg
greta2, end, https://www.youtube.com/watch?v=GlfW7aYouYQ
greta3, end, https://www.youtube.com/watch?v=2fycgrYgXpA
greta4, 21s, https://www.youtube.com/watch?v=DQWMDWWYVz4
climate change, 6s, https://www.youtube.com/results?search_query=climate+change
climate alarmism,6s, https://www.youtube.com/results?search_query=climate+alarmism
please note: the political positions confronted here are not equivalent. They are not equally comparable opinions, because decades of research confirm the climate emegency we are living on. Simply we can’t assume YouTube cares, or that YouTube algorithm might judge with their automated tools (and of course the underpay human labor).
urltag, watchFor, url
naomi1, end, https://www.youtube.com/watch?v=8LnZbAsws20
naomi2, end, https://www.youtube.com/watch?v=HxX-1cWSvVc
naomi3, end, https://www.youtube.com/watch?v=v8dXpe1Pp6Q
naomi4, 21s, https://www.youtube.com/watch?v=NlIzY12D2Z0
climate change, 6s, https://www.youtube.com/results?search_query=climate+change
climate alarmism,6s, https://www.youtube.com/results?search_query=climate+alarmism
## 💻 Register a CSV (this is a step you might skip)
Claudio@bluelizard MINGW64 ~/VMShared/yttrex/methodology (master)
$ ./dist/guardoni-win.exe --csv examples/climateChange/greta-v2.csv
CSV mode: mandatory --comparison or --shadowban; Guardoni exit after upload
Error in uploading the --csv. You must specify if:
it is a shadowban test with --shadowban
it is an experiment by comparison, with --comparison
In our case, we’re configuring an experiment that wants to compare how different profiles get served, therfore is a comparison kind of experiment. For the shadowban, a dedicated page would be written.
Claudio@bluelizard MINGW64 ~/VMShared/yttrex/methodology (master) $ ./dist/guardoni-win.exe --csv examples/climateChange/greta-v2.csv --comparison CSV mode: mandatory --comparison or --shadowban; Guardoni exit after upload guardoni:yt-cli Getting ready for directive type [comparison] +0ms guardoni:yt-cli Registering CSV examples/climateChange/greta-v2.csv as comparison +2ms guardoni:yt-cli Read input from file examples/climateChange/greta-v2.csv (407 bytes) 6 records +2ms guardoni:yt-cli CSV validated in [comparison] format specifications +2ms Directive from CSV created: experimentId d75f9eaf465d2cd555de65eaf61a770c82d59451 Claudio@bluelizard MINGW64 ~/VMShared/yttrex/methodology (master)
Long story short: the CSV must be registered in the server, so by getting that experimentId, anyone can repeat the same steps.
If the same CSV is uploaded twice, the ID returned is the same, and no effect happens.
Now we’ve two experimentId, one configured with Greta’s video and the other with Naomi’s:
- Greta d75f9eaf465d2cd555de65eaf61a770c82d59451
- Naomi 37384a9b7dff26184cdea226ad5666ca8cbbf456
## 💻 Once the experiment is registered, anyone can participate by typing:
./guardoni-win.exe –experiment d75f9eaf465d2cd555de65eaf61a770c82d59451
and then let the browser operate autonomously.
## 💻 TODO: how to download results, and the experiment page.
## 💻 TODO: advanced options.
## 💻 ...a name like this should have a backstory!
Guardoni /ˈɡwardoni
French: Les voyeurs. English: Peeping Toms, Voyeurs. Spanish: Mirones. Brasilian: Toms de espreitar.
TL;DR: while we were working on an investigation on the adult mainstream portal then become clear we need to program something that would watch that content for us; you know mental health matter. The tool later on become handy to repeat profiling methodologies, and thus have been generalized for youtube, tiktok, and other platform we support. Before this tool, most of our researches that include controlled profiling, were done by piloting the profiles manually.
Build
If you want to build your own executables, this is the process:
Clone this repository: https://github.com/tracking-exposed/yttrex/
Entrer the directory: cd yttrex/methodology
Run the node script: bin/guardoni.js
Build exes with command: npm run pkg
and check the dist directory